Process Extraction From Text
PET: An Annotated Dataset for Process Extraction from
Natural Language Text Tasks
Patrizio Bellan, Chiara Ghidini, Mauro Dragoni, Han van der Aa, Simone Paolo PonzettoFondazione Bruno Kessler, University of Mannheim
Trento (Italy), Mannheim (Germany)
{pbellan, ghidini, dragoni}@fbk.eu, {han, simone}@informatik.uni-mannheim.de
Abstract. Process extraction from text is an important task of process discovery, for which various approaches have been developed in recent years. However, in contrast to other information extraction tasks, there is a lack of gold-standard corpora of business process descriptions that are carefully annotated with all the entities and relationships of interest. Due to this, it is currently hard to compare the results obtained by extraction approaches in an objective manner, whereas the lack of annotated texts also prevents the application of data-driven information extraction methodologies, typical of the natural language processing field. Therefore, to bridge this gap, we present the PET dataset, a first corpus of business process descriptions annotated with activities, gateways, actors, and flow information. We present our new resource, including a variety of baselines to benchmark the difficulty and challenges of business process extraction from text. PET can be accessed via huggingface.co/datasets/patriziobellan/PET
Keywords: Process Extraction from Text, Business Process Management, Information Extraction, Natural Language Processing, Dataset, Gold Standard
The article can be downloaded here
Annotation guidelines can be downloaded here
The INcePtion schema che be downloaded here.
The dataset (version 1.0.1) can be downloaded here
Python dataset reader (alpha version) to interact with the dataset can be found here
The image below shows the annotation schema adopted to annotate process descriptions.
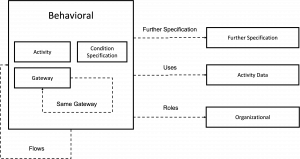
The annotation schema adopted to annotate PET dataset